Chapter 4: Encoding and Evolution
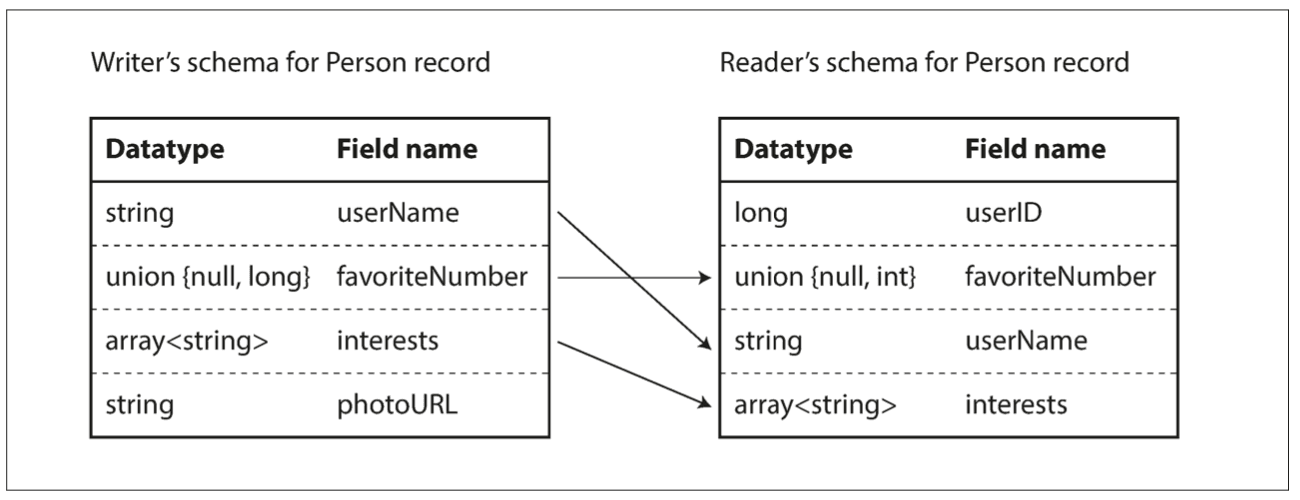
Your system doesn’t break when you deploy it. It breaks when old data meets new code. That’s the uncomfortable reality of software: data outlives everything. You can rewrite your frontend. You can refactor your backend. You can even replace your database. But your data? It sticks around quietly waiting to expose every bad decision you made six months ago.
Why Your Data Format Will Betray You (If You Let It)
Most engineers obsess over:
frameworks
databases
performance
But quietly running underneath everything is something way more fragile:
How your data is encoded.
And worse…
How it changes over time.
Because your system won’t break on day one.
It’ll break six months later—when version 3 of your API meets version 1 of your data.
The Real Problem: Data Outlives Code
Here’s the uncomfortable truth:
Code is redeployed all the time
Data sticks around forever
That means:
👉 Old and new versions must coexist
This is where most systems start to rot.
Encoding: Turning Objects Into Bytes
Before data is stored or sent over the network, it must be encoded.
Think:
const user = {
name: "Frank",
age: 30
};
Becomes:
JSON
XML
Protocol Buffers
Avro
etc.
Why Encoding Matters
Because different formats affect:
Performance
Size
Compatibility
Developer sanity
Human-Readable vs Binary Formats
Let’s break it down.
JSON / XML (Human-Readable)
Pros:
Easy to debug
Widely supported
Flexible
Cons:
Bigger size
Slower parsing
No strict schema
👉 Great for APIs, not always for internal systems.
Binary Formats (Protobuf, Avro, Thrift)
Pros:
Compact
Faster
Strong schema support
Cons:
Harder to debug
Requires tooling
👉 Great for:
Microservices
High-performance systems
Data pipelines
The Real Boss Fight: Schema Evolution
This is the heart of Chapter 4.
How do you change your data structure… without breaking everything?
Two Key Compatibility Types
1. Backward Compatibility
New code can read old data
✔ Required when:
You deploy new services
Old data still exists
2. Forward Compatibility
Old code can read new data
✔ Required when:
Rolling deployments
Multiple versions running at once
👉 In real systems, you need both.
JSON: Flexible… but Dangerous
JSON doesn’t enforce schemas.
Sounds great… until:
Fields are missing
Types change
Naming becomes inconsistent
Example:
// Version 1
{ "name": "Frank" }
// Version 2
{ "fullName": "Frank Mendez" }
Boom. Silent bugs.
The Hidden Truth
JSON is not schemaless.
The schema just lives in your code.
And your code is… inconsistent.
Binary Formats: Built for Evolution
Formats like Avro and Protobuf solve this properly.
How They Do It
They use schemas with versioning rules:
Fields have IDs
Unknown fields are ignored
Defaults can be defined
Example (Protobuf-style thinking)
message User {
string name = 1;
int32 age = 2;
}
If you later add:
string email = 3;
Old systems:
Ignore
email
New systems:
Handle it properly
👉 No drama. No production fire.
Avro’s Big Advantage
Avro stores schema separately from data.
That means:
Data is smaller
Schema can evolve independently
👉 Perfect for:
Kafka
Data pipelines
Event-driven systems
Data Evolution in the Real World
This is where things get spicy.
Scenario: Microservices
Service A sends data
Service B consumes it
They deploy independently
If your encoding is fragile:
💥 You break production
Scenario: Databases
You change schema:
ALTER TABLE users ADD COLUMN email;
Now:
Old code doesn’t know about it
New code depends on it
Welcome to migration hell.
Strategies That Actually Work
1. Add Fields, Don’t Remove
Safe:
{ "name": "Frank", "email": "..." }
Dangerous:
{ "fullName": "Frank" } // renamed field
2. Use Defaults
Always assume:
Field might be missing
3. Never Reuse Field Meaning
If status = 1 meant “active” before…
Don’t suddenly make it mean “pending”.
That’s how bugs become legends.
4. Version Your APIs (But Don’t Abuse It)
Versioning helps, but:
If you rely on versioning too much, your system becomes a museum.
RPC vs REST: Encoding in Communication
Chapter 4 also touches on service communication.
REST (HTTP + JSON)
✔ Simple
✔ Debuggable
❌ Loose contracts
RPC (gRPC, Thrift)
✔ Strong contracts
✔ Efficient
❌ Tighter coupling
👉 Trend today:
External APIs → REST
Internal services → gRPC / binary
Message Passing (Async Systems)
Instead of direct calls:
Services communicate via messages (Kafka, queues)
This makes encoding even more critical:
Messages might be consumed days… or weeks later.
So compatibility isn’t optional—it’s survival.
The Big Idea
Chapter 4 boils down to this:
Data systems must evolve without breaking.
And that requires:
Careful encoding choices
Strong compatibility guarantees
Discipline (yes, the boring part)
Practical Takeaways (Engineer Survival Kit)
1. Data format is a long-term decision
Changing it later is painful.
2. JSON is fine… until it isn’t
Use it for APIs, not everything.
3. Prefer schema-based formats internally
Avro / Protobuf > raw JSON for systems
4. Design for evolution from day one
Assume:
Fields will change
Services will version
Data will live forever
5. Backward compatibility is non-negotiable
Break it once → regret it forever
Final Thoughts
Chapter 4 is where you realize:
Building systems isn’t just about writing code.
It’s about designing change.
Because in real life:
Requirements change
Teams change
Systems evolve
And your data has to survive all of it.
Stay in the loop
Get notified when new posts are published. No spam, unsubscribe anytime.
No spam · Unsubscribe anytime