Chapter 5: Replication
Just copy the data to another server.
Why Copying Data Is Harder Than It Sounds
At first glance, replication feels obvious:
“Just copy the data to another server.”
Done, right?
Not even close.
Because the moment you replicate data, you introduce:
Inconsistency
Latency
Failures
And a whole new category of bugs that only show up at 3AM
Welcome to distributed systems.
Why Replication Exists
We replicate data for three main reasons:
1. Reliability
If one machine dies, your system shouldn’t.
2. Scalability
More replicas = more machines to handle reads
3. Latency
Put data closer to users (geo-replication)
Simple goals.
Complicated consequences.
The Core Problem: Keeping Data in Sync
Once you have multiple copies of data:
How do you make sure they all agree?
Short answer:
You don’t always.
And that’s where replication strategies come in.
Leader-Follower Replication (Primary-Replica)
The most common model.
How it works:
One node = leader (handles writes)
Other nodes = followers (replicate data)
Writes go to leader → propagated to followers
Sounds clean… until:
Followers lag behind
Network fails
Leader crashes
Two Modes of Replication
Synchronous Replication
Leader waits for followers to confirm writes
✔ Strong consistency
❌ Slower writes
❌ Risk of blocking
Asynchronous Replication
Leader doesn’t wait
✔ Fast writes
❌ Risk of data loss
❌ Replicas may be stale
👉 Most systems use asynchronous replication.
Because speed wins… until it doesn’t.
The “Read After Write” Problem
Classic bug.
You:
Write data to leader
Immediately read from follower
Result:
👉 Data is missing
This is called eventual consistency
The system will eventually become consistent…
just not when you need it.
Fixes:
Read from leader after write
Track user session → route to leader
Use “read-your-writes” consistency
Replication Lag: The Silent Killer
Followers are always behind the leader (even if by milliseconds).
That delay can cause:
Missing data
Outdated views
Confusing user behavior
Real-world example:
You post something → refresh → it’s gone.
Not deleted. Just… not replicated yet.
Handling Node Failures
Machines fail. Always.
So what happens when the leader dies?
Failover
System promotes a follower to become the new leader.
Sounds easy… but:
Which follower is most up-to-date?
What if two nodes think they’re leader?
What about lost writes?
👉 This is where systems get complicated fast.
Split Brain (The Nightmare Scenario)
Network partitions happen.
Now:
Node A thinks it’s leader
Node B thinks it’s leader
Both accept writes.
💥 Data conflict chaos.
Fixing this requires:
Consensus algorithms
Leader election protocols
(That’s Chapter 9 territory—brace yourself.)
Multi-Leader Replication (Write Anywhere)
Instead of one leader:
👉 Multiple nodes accept writes
Useful for:
Multi-region systems
Offline-first apps
Collaboration tools
But here’s the cost:
❌ Conflicts are inevitable
❌ You must resolve them
Example:
Two users edit the same record in different regions.
Now what?
Last write wins?
Merge changes?
Ask the user?
👉 There is no perfect answer. Only trade-offs.
Leaderless Replication (Dynamo-Style)
No leader. No hierarchy.
Every node can accept reads/writes.
How it works:
Write sent to multiple nodes
Read collects responses
System reconciles differences
Concepts you’ll meet:
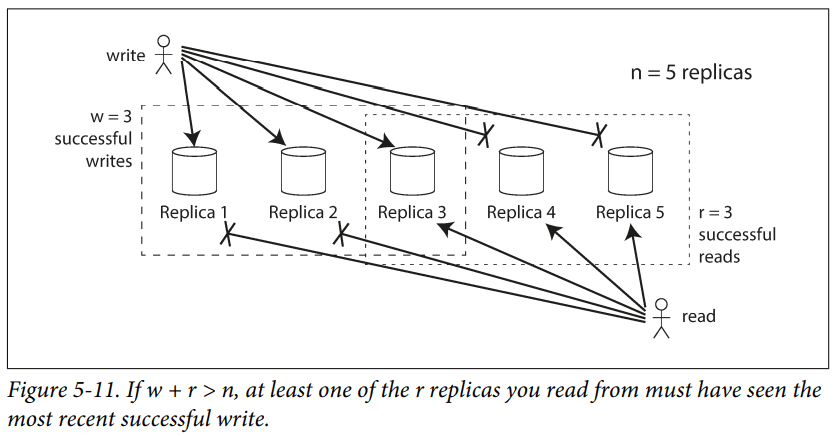
Quorum reads/writes
Read repair
Anti-entropy
Pros:
✔ High availability
✔ Fault tolerant
Cons:
❌ Complex conflict handling
❌ Eventual consistency everywhere
Used by:
DynamoDB
Cassandra
Riak
Eventual Consistency: The Reality Check
Let’s be honest:
Strong consistency is expensive.
So many systems settle for:
👉 Eventual consistency
Meaning:
Data may be temporarily inconsistent
But will converge over time
The trade-off triangle:
You can’t have all three:
Consistency
Availability
Partition tolerance
(Yes, the famous CAP theorem lurking in the background.)
Practical Patterns That Actually Work
1. Accept Staleness Where It’s Okay
Social feeds → fine
Banking → absolutely not
2. Use Leader-Based for Simplicity
Start here unless you have a reason not to.
3. Monitor Replication Lag
If you don’t measure it, you will regret it.
4. Design for Failure
Assume:
Nodes will crash
Networks will fail
Data will diverge
5. Conflict Resolution Is Your Problem
No database magically solves it.
You decide:
Merge logic
Conflict rules
User experience
The Big Idea
Chapter 5 is basically saying:
Replication is easy to start… and hard to get right.
Because once data is duplicated:
You lose a single source of truth
You gain distributed complexity
Final Thoughts
Replication is where systems stop being simple.
It forces you to think about:
Time
Failure
Consistency
And once you go distributed…
There’s no going back.
Stay in the loop
Get notified when new posts are published. No spam, unsubscribe anytime.
No spam · Unsubscribe anytime